Before I go any further on S/4 HANA I want to talk about the SAP HANA itself. But to understand the SAP HANA, it is necessary to talk about hardware innovation and In-Memory.
In this blog post, I will cover only the highlights of this subject. I do recommend the lecture of a book if you want to go in more details:
The In-Memory Revolution: How SAP HANA Enables Business of the Future – By Hasso Plattner, Bernd Leukert
SAP HANA is a combination of hardware and software made to process massive real time data using In-Memory computing and everything started in 2006, when Professor Hasso Platner came with this idea, which now reinvents Enterprise Computing, focusing in a new database for enterprise applications, a database suitable for in-memory persistence and removing aggregates.
For many years, the enterprise systems were built with help of aggregates based on the assumption that would improve system response for most of the business applications across the different business areas in the company (from Sales & Logistics to Finance & Controlling). The aggregates are so popular that most of the database training guides starts with them.
But why to remove aggregates then?
 image source: SAP
image source: SAP
Aggregates exist since the 60’s decades when IBM introduced the punch cards along with the tapes reader.
Maintaining the aggregates is a bottleneck. So why do we do the aggregates? The aggregates were built for performance.
Are those aggregates still necessary in 2014? No.
Traditional applications were built on a hierarchical data model. Detailed data was summarized into higher-level layers of aggregates to help system performance. On top of aggregates there were more aggregates and special versions of the database tables to support special applications. So as well as storing the extra copies of data, it was also necessary to build application code to maintain extra tables and keep them up to date.
In addition to aggregates, there is another inefficiency that needs to be mitigated. Database indexes improve access speed because they are based on common access paths to data. But they need to be constantly dropped and rebuilt each time the tables are updated. So again, more code is needed to manage this process.
So the traditional data model is complex and a complex data model causes the application code to be complex. It has been found that up to 70% of application code is built specifically for performance of an application and adds no value to the core business function.
With a complex data model and complex code, integration with other applications and also enhancements are difficult, and simply not agile enough for today’s fast moving environment.
Remove complexity with SAP S/4HANA
Using the power of SAP HANA it is possible to aggregate on the fly in sub seconds from any line item table without the need of pre-built aggregates. SAP HANA can generate any view of the data at runtime, all from the same source tables.
SAP HANA organizes data using column stores, which means indexes, are usually not needed (offer little improvement). Later, I will discuss in this blog how the Column Stores work.
So as well as losing the aggregates and indexes from the database, it is possible also to lose huge amounts of application code that deals with aggregates and indexes, and live with a simplified core data model and also simplified application code.
Hardware enabling rethink
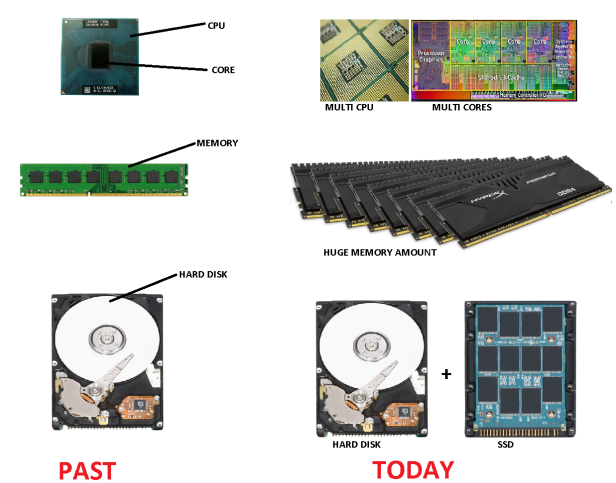
The SAP HANA took advantage of the quick hardware evolution.
Years ago, memory was very expensive, and for this reason, only small amounts of memory were available across the company’s servers. The limitation on memory was a obstruction in the data flow from Hard Drive to CPU. The CPU was always idle waiting for the data to arrive through a narrow gateway.
With memory been more accessible, prices dropping, huge amounts of memory are available in the companies, terabytes of them, that made possible to rethink how data would flow to CPU, eliminating the existing waiting times. Following the fact that huge memory becomes available, processor’s industry improved at an extraordinary rate, with high speed multi-core processors allowing the most complex tasks to be processed in parallel, carrying out real-time elaborated analytical tasks, such as predictive analysis.
Taking the SAP applications wrote along of 20 years and making them work in the new hardware would wasn’t an option. It would have some gain for sure, but the classic database as we know and the applications were designed over a restricted hardware architecture, that means, they would not be able to explore the maximum power of the new hardware.
That was when SAP decided that the database would have to be reinvented.
Main memory is 125.000 faster than disk
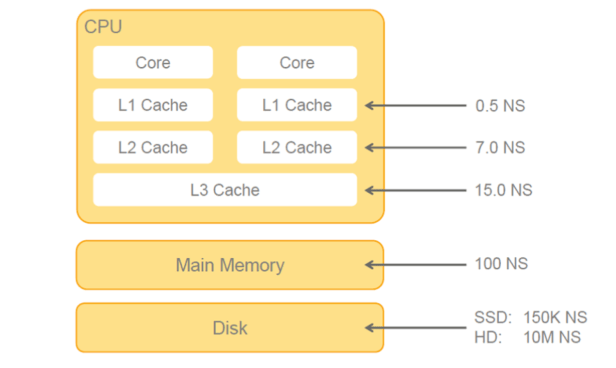 image source: SAP
image source: SAP
As you can see in the diagram above, the time necessary to get data to the core processing is longer as it gets away from the core. That means, Hard Disk is the works performer by a big significant amount of time.
For many years disk access has been pushed to the limit and now performance become restricted by the basic physics rules of the spinning disk.
Modern CPU processors are built with CPU cache in layers, which allows managing on-board memory in a very efficient way.
But what is a nanosecond?
According to Wikipedia, A nanosecond (ns) is a SI unit of time equal to one billionth of a second (10−9 or 1/1,000,000,000 s). One nanosecond is to one second as one second is to 31.71 years. A nanosecond is equal to 1000 picoseconds or 1⁄1000 microsecond. Because the next SI unit is 1000 times larger, times of 10−8 and 10−7 seconds are typically expressed as tens or hundreds of nanoseconds.
So a nanosecond is fast, very fast and it is how processor speeds need to perform for modern application in a digital economy.
SAP spent the last year working closely with CPU manufacturers in product’s co-development projects to understand better how to explore and make maximum efficient usage of all the power from their processors, understanding how data moves from memory to core.
Hard disks are still needed for now, for logging and backups but eventually even that will go away in favor of other technologies such as SSD (solid state drive).

In my next post I will summarize what I learned about Column-store, data compression and etc.

Ótima apresentação. Seria ótimo uma visão tua acerca do simple logistic e seus impactos nos processos localizados no Brasil comparados com a realidade que vive fora do país.
LikeLiked by 1 person
Oi Leopoldo… está na minha lista fazer esse trabalho e colocar essa comparação aqui. O objetivo é mesmo verificar como o S/4 se encaixa na localizacao e vice e versa… Mas antes eu preciso explorar mais a base disso tudo (O HANA, in Memory, Column Store e etc).
LikeLike
thanks for sharing the information,,,useful one
LikeLike
Hello,
This article is very informative.I really liked it.
Thanks for sharing such a good article,
LikeLike
Hi,
Being new to the technology, this post taught me many things. I occasionally find these kinds of articles with snippets. nice informative post on
SAPHANA.
thanks a lot.
LikeLike